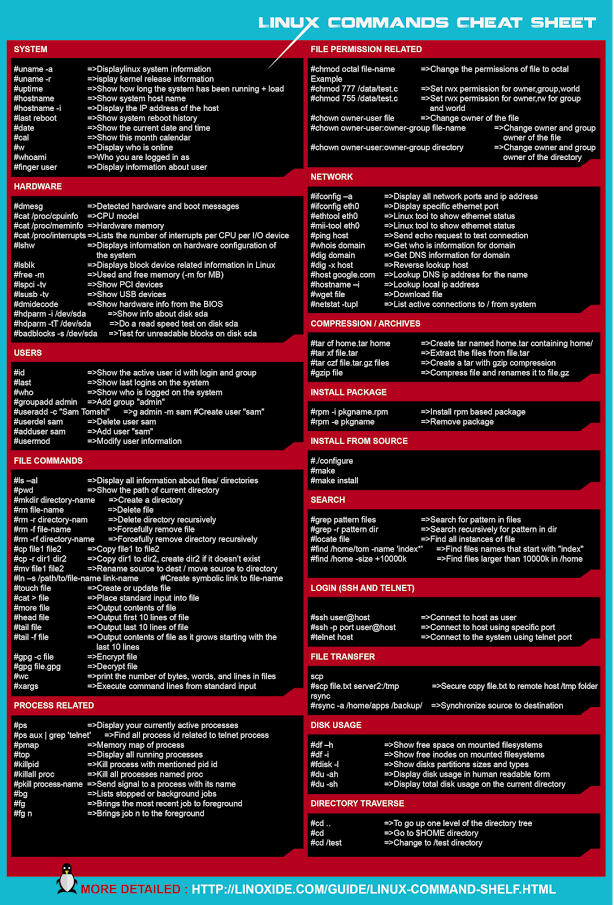
리눅스 자주쓰는 명령어 모음입니다.
^^ 잘 활용합시다 :)
리눅스 자주쓰는 명령어 모음입니다.
^^ 잘 활용합시다 :)

자료구조 카테고리 추가되었습니다.
컴퓨터 공학의 꽃은 알고리즘이요.
컴퓨터 공학의 꿀벌은 자료구조 이니라…
저는 사실 자료구조의 중요성을 늦게 깨우쳤습니다 ㅠㅠ…
하지만 지금이라도 늦지 않았다고 생각합니다. ! 빠샷 :)
위키에 다음과 같은 말이 있네요
신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다.
맞습니다.. 자료구조는 알고리즘을 지탱하는 큰 뿌리이며,
대동맥 혈관 같은 중요한 녀석 입니다.
그럼 앞으로 자료구조 깨부수기 시작합니다.

– 공부하다 죽어라 !!!-
역자 주 : 이 글은 <Case Study – Node at LinkedIn: The Pursuit of Thinner, Lighter, Faster> 의 번역입니다. 인터뷰를 번역한 내용이다 보니 중간에 약간은 맥락이 끊기는 듯한 부분이 있을 수 있습니다. 또한 원문을 그대로 옮기기 힘들어 의역을 넣은 부분들이 많이 있습니다. 가능하면 인터뷰의 원래 내용을 그대로 전달하고자 노력했지만, 아쉬운 부분이 있는 것 또한 사실입니다. 미심쩍은 부분에 대해서는 원문을 참고해주시면 감사드리겠습니다. 번역 피드백 환영합니다. (한대희 – nyamx2@gmail.com)
확장성있는 네트워크 어플리케이션 개발을 위한 자바스크립트 기반의 서버 사이드 소프트웨어 플랫폼인 Node.js는 많은 개발자들을 열광케 했습니다. 그 인기가 다른 개발자들까지 자극하게 되어 몇몇 사람들은 Node의 단점에 대한 부정적인 블로그 포스팅들을 쏟아내게 만들기도 했지요. 새롭지만, 한편으로는 아직 충분히 검증되지 않았음에도 불구하고 Node는 점점 많은 변화를 유발시키고 있습니다.
2011년 링크드인 (LinkedIn) 은 그들의 핵심 모바일 서비스를 Node로 재작성하기로 결정했습니다. Ruby on Rails 기반으로 운영되어 왔던 직장인 네트워킹 서비스 링크드인은 성능과 확장성을 향상시킬 방법을 찾고 있었습니다. 블락을 하지 않는 (Non-blocking) 언어 구조와 싱글 스레드 이벤트 루프를 전반적으로 사용하고 있는 Node는 좋은 결과를 보여줄 것 같았습니다.
Ryan Dahl (현재 Joyent 에서 근무중이며, Node를 후원 및 유지 중) 이 2009년에 Node.js를 처음 만들고난 후, 개발자들이 Node에 흥미를 가지기 시작하기까지는 오랜 시간이 걸리지 않았습니다. Node는 웹 어플리케이션의 클라이언트 사이드와 많은 연관성이 있는 언어인 자바스크립트를 사용하는데, 이는 클라이언트 사이드를 개발하던 개발자들로 하여금 서버 사이드에 그에 대응하는 함수를 구현하는 일을 보다 쉽게 만들었습니다.
Kiran Prasad는 모바일 엔지니어링 부분의 senior director로 (한국에서 팀장급과 유사) LinkedIn에 2011년 입사하여 Node로의 전환을 주도했습니다. 현재 링크드인의 모바일 프론트엔드 서버는 순수하게 Node로 이루어져 있습니다. Prasad는 Node가 모든 작업에서 최고의 도구는 아니라는 것을 인정합니다. 하지만 그와 그의 팀이 링크드인의 시스템을 분석한 결과, 시스템의 효율성을 높이기 위해서는 이벤트 기반의 시스템이 필요할거라고 결론내렸습니다. 또한 Node는 데이터 객체를 직접 조작하는 것이 가능하면서도 가볍고 빨랐기 때문에 매력적이었습니다.
Prasad는 다년간 Palm사와 Handspring사에서 WebOS 플랫폼 위에 작동하는 모바일 앱을 경험했고, 모바일 웹 소프트웨어 개발자로서도 활동한 경험이 있었기에 (Silced Simple사에서는 CEO로, Aliaron사에서는 CTO로) LinkedIn에서 그의 업무를 수행할 준비가 되어 있었습니다.
이 글에서 그는 Kelly Norton, Terry Coatta와 함께 링크드인의 Node.js 도입에 대해 이야기합니다. Norton은 차세대 마케팅 툴을 개발하는 Homebase.io의 공동 창업자이며, 이전에는 구글 웹 툴킷(GWT)을 처음으로 개발한 소프트웨어 엔지니어입니다.
KELLY NORTON (KN) LinkedIn이 어떻게 Node.js를 도입하게 되었는지 말씀해 주시죠.
KIRAN PRASAD (KP) 당시 저희는 루비 온 레일즈의 프로세스 기반 시스템을 사용하고 있었고, 이 시스템이 우리가 원하는 만큼 확장(scale)하지 못할 것이라는건 명확했습니다. 물론 당신이 거기다 돈을 쏟아 부을 준비가 되어 있다면 시스템을 확장하는 것은 가능합니다. 하지만 그게 옳은 길 같지는 않았어요. 그리고, 모바일 모델에서는 – 엄청나게 많은 마이크로 커넥션이 존재하는 – 프로세스 기반의 루비 온 레일즈 스택은 문제가 생기리라는 사실을 예측했습니다.
또한 그 당시 사용하고 있던 루비 인터프리터의 버전이 작은 String 객체를 가비지 컬렉션하는 데에 뛰어나지 못했기 때문에, 문자열 조작을 많이 사용하는 우리의 어플리케이션은 레일즈 환경에서 커다란 성능 저하가 있었습니다. 또한 우리는 백엔드에서도 JSON 형태로 데이터들을 받고 프론트엔드에서도 JSON 형태의 데이터가 필요한데, 레일즈는 JSON 조작에 최적화되어 있지도 않았습니다.
Ruby on Rails는 보다 웹 스택에 가까운 쪽으로 설계되었다는 사실은 명확합니다. 레일즈의 진짜 가치는 앱과 컨트롤러에 제공하는 템플릿 구조와 프레임웍 컨셉들이니까요. 하지만 클라이언트 사이드의 렌더링을 할 때는, 컨트롤러와 뷰가 클라이언트 사이드로 내려가게 됩니다. 그게 모바일 시스템에서 발생하는 일이죠.
또한 링크드인같은 곳에서 볼 수 있는 여러개의 스택이 있는 대용량 시스템에서는, 모델(MVC에서의 그 모델 – 역자 주)을 더 세밀한 단위로 분리하기 시작하게 됩니다. 즉, 그와 같은 상황이 오면 다른 서버나 서비스 레벨로 한 단계 내려갈 수밖에 없기 때문에 더이상 Rails의 Active Record의 범위 안에 있지 않다는 말이죠. 이로 인해 중간 레이어는 매우 얇아지고 문자열을 조작하는 정도의 역할만을 수행하게 됩니다.
그래서 조사를 시작하고 우리는 생각하게 되었죠. “더 이상 이건 여기에 맞는 도구가 아닌 것 같아. 이건 우리가 지금 이루고자 하는 바를 위해 디자인되지 않았어.” 그럼 무엇을 사용해야 할까요? 우리가 찾고 있는게 뭔지는 모르겠지만 이벤트 기반이어야 하고, 문자열 조작에 뛰어나야 하고, 빠르고 가볍고 사용하기 쉬워야 했습니다. 우리는 루비의 EventMachine이나 파이썬의 Twisted같은 이벤트 기반의 프레임웍을 조사하기 시작했습니다. 비록 지금은 Play가 예전보다는 조금 더 유명해졌지만 우리가 조사를 시작했을 2011년 초에는 이벤트 기반의 Java 프레임웍은 메인스트림이 아니었기 때문에 우리의 고려대상에 들어가지 못했습니다.
KN 하지만 이벤트 기반이라는 점을 제외하면 Node의 어떤 점이 그렇게 매력적인가요?
KP 우리는 Node를 가지고 몇 개의 부하 테스트를 실시했습니다. 다른 6개의 서비스에 request를 보내고, 데이터를 가져와서, 합치고, 다시 되돌려 보내는 간단한 작업이었죠. 테스트 결과 50,000 QPS(Queries Per Second)정도를 얻었습니다. 게다가 기존의 시스템에 비해 20배정도 빠르고, 메모리 사용량(Memory Footprint) 역시 더 작다는 사실을 발견했습니다.
또한 명백하게도 Node.js는 기술적인 부분 이외에서도 장점이 있었습니다. JavaScript는 많은 사람들이 이해할 수 있고 코딩하는 데에 어려움이 없는 언어입니다. Node가 당시 과도한 유행을 타고 있다는 점 또한 크게 문제가 되지는 않았습니다 – 지금도 그렇구요. 어떤 면에서는 인력을 구하기 더 쉬워진 면도 있습니다.
TERRY COATTA(TC) 모델 표현에 루비의 액티브레코드를 사용하는 부분을 제거하셨는데, 그 모델이 아예 사라지는 것이 아니라 어딘가에는 존재해야한다는 사실은 명확합니다. 모델을 위해 이미 가지고있는 인프라 스트럭쳐를 미들웨어에 사용하지 않는 이유는 뭔가요?
KP 모델들은 객체(object)와 유사하게 디자인 되어 있습니다. 모델에는 속성(property)가 있고, 메소드(method)가 있습니다. 또한 구조화되어있고 정적인 타입을 가지기 때문에, 당신은 객체가 변질되지 않게 만들어 각각의 객체가 무엇인지 정확하게 있는 환경을 만들기 위해 노력합니다. 우리 모두가 처음 객체 지향 디자인을 접할 때 배웠던 방식 바로 그대로요.
그래서 당신은 조금 더 객체 지향으로 설계된 언어가 이와 같은 시스템을 만드는 데 이상적일 것이라고 생각할 수도 있습니다. 하지만 모델은 결국 뷰 컨트롤러 밖으로 나가게 되지요. 모바일 시스템에서는 뷰 컨트롤러가 클라이언트로 이동합니다. 그럼 이런 질문이 생기지요: 중간에는 뭐가 남는가? 기본적으로 거기 남는 것은 데이터들의 해시(hash)를 효율적으로 조작해서 포맷하는 함수들의 뭉치만이 남게 됩니다. 결국 약간의 취합(aggregation)과 포맷팅만이 남는 거죠.
제가 Node.js를 선택했을 당시에 이 사실을 명확히 알고 있었다고 확신하지는 않습니다. Node를 몇 년간 사용하고 나니, 중간 층에는 당신의 프론트 엔드 (이제 이건 클라이언트와 동일하죠) 와 백엔드 (이게 아마 당신의 데이터 모델일것입니다)를 이어주는 접착제가 있어야 한다는 것이 명확해졌고, 사실 이 역할은 함수형 언어가 최고의 효율을 발휘할 수 있는 곳입니다. 현재 우리는 모든 백엔드를 Java로 작성하고 있고, 우리가 사용하고 있던 모든 Java 스택들은 조금 더 프로세스 기반에 가깝습니다.
TC Node.js를 미들웨어 레이어에 사용하는 경험을 하셨지 않습니까. 그럼 이걸 백엔드에 사용하는 것도 고려하고 있나요?
KP 현재 우리는 모바일에 특화된 데이터 스토어를 개발하고 있고, 이를 Node.js와 자바스크립트로 개발해야 하는지를 분석했었습니다. 우리 팀은 Node보다는 조금 더 정적인 타입을 가지고 있는 언어를 원했던 것 같습니다. 사실 저는 조금 더 정적 타입을 가지는 고전적인(classic) 프로그래밍을 피하려고 노력했지만, 우리 팀은 정해진 메소드와 속성과 함께 객체를 정의함으로써, 그래서 다른 누군가가 그걸 망쳐놓기 힘들게 만들길 강력히 원했습니다. 그들은 단지 외부의 누가 그 프로토타입을 갈아엎거나 거기에 무슨 짓을 하는 것을 원치 않았죠. 여전히 성능 관점에서 저는 이벤트 기반의 프레임웍을 더 선호합니다. 현재 우리는 내부적으로 이 백엔드와 데이터 스토어같은 것들에 Rest.li를 사용하고 있는데, 왜냐하면 이벤트 기반의 무언가가 우리의 아키텍쳐를 변화시켰다고 믿기 때문입니다.
TC Node.js에서 관찰된 퍼포먼스 향상이라는 관점의 관점에서, 미들웨어 레이어를 위해 다른 언어 위에서 돌아가는 가벼운 프로토타입들을 만들어보았나요?
KP 우리는 이벤트 기반 프레임웍인 EventMachine과 Twisted를 사용하여 루비와 파이썬으로 프로토타이핑을 해 보았습니다. 결론적으로 Node는 순수 처리량 (throughput) 측면에서 2~5배가 더 빨랐습니다. 더 흥미롭고, 결정적으로 우리로 하여금 Node를 고르게 한 점은 Node를 사용한 프로토타입을 만드는 데에는 두시간 내지 세시간 정도가 걸린 반면 EventMachine이나 Twisted를 사용했을 때는 하루이틀이 걸렸다는 겁니다. 단지 더 다운로드받아야 하는 것들이 많아졌다는 이유만으로요.
예를 들어, 파이썬을 사용할 때 당신은 파이썬의 표준 HTTP 라이브러리를 사용하는 대신 비동기 HTTP 라이브러리를 사용하고 있는지를 확인해야 합니다. 우리가 무엇을 하려고 해도, 파이썬 표준 라이브러리를 사용할 수가 없어요. 대신 Twisted 버전으로 반들어진 특별한 라이브러리를 사용해야 합니다. 루비에서도 이 사실은 마찬가지에요. 커뮤니티의 다른 모두들도 마찬가지였겠지만, 우리는 Node를 가지고 시작하는것이 얼마나 더 쉬운지 알아냈어요. 우리에게 필요한 모든 것이 기본적으로 갖추어져 있으니까요. 게다가, Node를 사용하여 개발하는 것이 훨씬 더 빠르다는 것 또한 매우 중요한 사실이었죠. 성능만큼이나 생산성도 중요하니까요. 개발자들의 생산성 역시 중요합니다.
메모리 풋프린트도 또 하나의 요소입니다. 우리는 각각의 언어에서 VM(virtual machine)들이 얼마나 잘 작동하는지를 살펴봤는데, V8 자바스크립트 엔진은 다른 모든 것들을 날려버렸어요. 우리가 50,000QPS로 이 모든 작업들을 할 동안 메모리는 20~25MB정도만을 사용했습니다. 하지만 EventMachine이나 Twisted에서는 표준 라이브러리 이외에 비동기 작업에 필요한 클래스들을 로딩하는 것 만으로도 60~80MB를 소모했죠. 기본적인 레벨에서, Node는 반 정도의 메모리밖에 사용하지 않습니다.
자바스크립트의 함수형 언어적인 특성들을 마주하고 나자, 백엔드에서 오는 모든 데이터들을 일단 몇 개의 객체들과 메소드들로 변환해야겠다는 생각이 들지 않았습니다. 이는 또한 이 객체들의 계층적 구조나, 어떤 클래스가 하위 클래스인지, 부모 클래스인지, 전체적인 구조는 어떤지, 각각의 객체들간의 관계는 어떻게 되는지에 대해 알기 위해 노력하지 않아도 된다는 것을 의미합니다. 하지만 모델이나 객체 지향적인 시스템에선 그런 일들을 해야만 하죠. 이건 우리에게는 이런 뜻과 같았습니다. “자, 이제 넌 여기 있는 세 개의 엔드포인트들에 접속해서, 데이터들을 합치고 또다른 이 객체를 뱉어내면 되는거야.”
하지만 현실에선 객체는 단지 해시일 뿐입니다. 그렇죠? 당신은 인접해 있는 몇몇 물건들을 가져와서 다른 뭔가를 뱉어냅니다. 이건 어떤 흐름(stream)을 처리하는 필터를 가지고 있는 것과 같아요. 데이터는 흘러 들어와서 통과하고 반대편으로 나옵니다. 이런 방식의 사고를 통해 당신은 그 객체들이 무엇인지, 어떻게 작동하는지, 어떻게 상호작용 하는지를 무시할 수 있습니다. 그래서 우리가 원하는 목표에 조금 더 빨리 도달하게 해주죠.
우린 이제 몇몇 함수를 단위로 개발하고 있습니다. 지금은 함수들이 자기들이 원하는 것에 직접 접근합니다. 만약 함수 A가 ‘ 프로필’과 ‘회사’들과 ‘직업’ 정보를 받아서 그것들을 합치고 싶다면, 그 함수가 그냥 직접 그 정보들에 접근하는 겁니다. 그리고 만약 함수 B가 ‘프로필’과, ‘회사’와, 또다른 무언가에 접근하고 싶으면 그렇게 하는 거죠. 하지만 이 두 함수는 프로필이나 회사에 접근하기 위해 같은 함수형 인터페이스를 사용하고 있지는 않습니다. 문제는 만약 우리가 ‘회사’에 접근하는 과정에 버그가 있다면, 두 군데를 모두 고쳐야 하겠죠. 만약 제가 로깅을 추가해서 누군가가 ‘회사’에 접근하는 일이 일어나는 모든 인스턴스들을 보고 싶다 해도, 모든 것들이 하나의 통로(funnel)를 지날 만큼 중앙 집중(centralized)되어 있지 않습니다. 우리가 객체 레이어를 만들고 있지는 않지만, 우리는 이런 점들을 인식하고 있습니다. 최소한 RESTful한 API에 대해서는요. 우리는 각각의 리소스 타입 앞단에 존재하면서 커뮤니케이션을 수행할 몇몇 함수들을 만들어야 합니다. 이건 마치 인터페이스에 대한 프록시를 만드는 것과 같아요. 이것은 우리가 이런 일련의 과정을 통해서 알아낸 것들 중에 하나이고, 우리는 새로운 추상화 레이어를 만듦으로써 이를 바로잡기 시작했습니다.
TC 추가적으로 새로운 레이어를 만들기 위해서 코드를 리팩터링한다고 하셨죠. 만약 리팩터링에 소요되는 시간을 고려한다면, 만약 다른 접근방법을 사용하는것 만큼이나 지금의 코드 베이스를 만드는데 소모되는 시간이 비슷하게 될 것이라고 생각하시나요?
KP 이건 단지 코딩 자체를 하는데에 얼마나 시간이 걸리느냐 하는 문제가 아니기 때문에 그렇지는 않을 것 같네요. 이건 개발 과정의 다른 모든 부분들과도 관련이 있는 문제에요. 예를 들어, 당신이 앱을 작성하고 ‘Node’를 타이핑해서 앱을 실행시킨다면, 20~100ms 정도밖에 걸리지 않을겁니다. 루비를 사용한다면, 가끔씩은 레일즈 콘솔이 뜨는 데만 15~30초가 걸립니다. 제가 Node가 코딩에 관한 어떤 관점에서도 뒤떨어지는지에 대해서 이야기할 준비도 되어있지 않고요. 하지만 어찌됐든, Node는 더 가볍고, 얇고, 빠릅니다. 그래서 매일매일 저는 더 빠르게 개발하고 있습니다.
좀 더 구조가 잡힌 언어에서는, 컴파일이나 빌드하는 데에 발목을 잡히게 됩니다. 그러다가 결국 핫스왑이 되는 환경을 구성하게 되고, IDE가 이 환경에 연결해서 런타임 환경을 수정할 수 있도록 세팅해야 할겁니다. 대부분의 경우 이렇게 할 수 밖에 없는 것이, 어플리케이션을 로딩하기까지의 시간이 너무 오래 걸리고, 수정사항을 만든 다음엔 다시 로딩하는 과정을 거쳐야 하기 때문이죠. Node는 굉장히 빠르기 때문에 이런 일련의 문제가 없습니다.
리팩터링이 코딩하는 시간을 늘리고, 우리가 이런저런 것들을 자르고 불태우면서 (객체의 복잡함을 제거했다는 앞 문단의 다른 표현이라고 추측됩니다. – 역자 주) 느겼던 단순함의 즐거움을 어느 정도 뺏어가는 것도 사실이죠. 하지만 전체적으로 봤을 때는 Node가 굉장히 가볍고 빠르기 때문에 리팩터링 과정에서 드는 약간의 시간 소모를 감안하더라도, 전체적으로는 더 효율적이라고 생각합니다.
TC 만약 또 다른 프로젝트를 Node를 사용하여 시작한다면, 조금 더 내부적인 구조 설계를 가지고서 개발을 시작할 생각이 있나요?
KP 이건 꼭 Node에만 해당되는 질문은 아닌 것 같습니다. 이건 개인 취향에 달린 문제인데요, 제가 봤을 때 프론트엔드의 UI 코드는 길어봐야 1.5년에서 2년정도밖에 생존하지 못합니다. 아주 극소수의 코드들만이 5년에서 10년 정도를 버티지요. 제 생각에 이런 현상이 생기는 이유는 코드의 퀄리티에 문제가 있어서라기보다는 기술이 계속해서 발전하고, 대부분의 소프트웨어 엔지니어들이 4년 정도의 주기로 일을 하도록 권장받기 때문이지요. 계속해서 새로운 사람들이 들어와 당신의 코드를 검토할 것입니다. 전 단순히 탁자 하나를 보더라도, 뭔가를 보면 그것보다 더 나은 것을 만들 수 있을거라는 확신이 듭니다. 제 생각엔 이건 자연적인 현상인 것 같아요. 1.5년에서 2년 주기로 계속 새로운 사람들이 들어와 몇몇 코드 베이스들을 검토하고 이걸 더 발전시킬 수 있는지를 결정하는 것이죠.
이러한 사실에 비추어 생각해보면, 기존의 코드를 천천히 발전시켜 나가는 것보다 코드 한 덩어리를 조금 더 모듈화된 방식으로 완전히 다시 짜는 게 빠를 수도 있습니다. 혹은 한두달 정도의 시간을 투자해 전체 코드를 완전히 갈아 엎는게 더 빠를 수도 있지요. 제가 만약 이 프로젝트를 다시 한다고 해도 아마 전 같은 방법을 택할 겁니다. 어떤 상황에서라도 전 우선 프로젝트를 일단 만들어 놓고, 나중에 여기서 플랫폼이 될만한 무언가를 추출하는 쪽을 선호합니다. 처음부터 완벽한 플랫폼을 만들고 모든 컴포넌트들을 앞에 꺼내놓은 다음 올바른 순서대로 끼워 맞춰서 완벽한 플랫폼을 만드는 것보다요. 제 생각엔 프로덕션 환경에서 돌아가는 무언가를 만들고 나서 문제점이 대체 뭐였는지를 깨닫기 전까지는 그 ‘올바른 순서’라는게 무엇인지 깨닫는게 불가능하다고 생각합니다. 그러고 난 후에야 정말 어디서 라이브러리를 추출하고 그걸로 무엇을 해야하는지를 알게 되는거죠.
Node로 변경하자는 결정을 내린 후, Prasad의 팀은 구현과 유지보수에 가장 적합한 방법이 뭔지를 찾아내야 했습니다. Linkedin의 모바일 서비스 팀은 Ruby on Rails에 매우 익숙해져 있었기 때문에, 기존의 Rails 구조 중 일부를 Node.js의 구조와 혼합하여 구성함으로써 빠르게 프로젝트를 시작할 수 있었습니다. 팀의 구조가 작았던 덕분에, Prasad는 Javascript의 변경을 모니터링하면서 문제들을 빠르게 감지할 수 있었습니다.
Node.js는 이벤트 기반의 프로그래밍으로 이루어져 있기 때문에 상당히 다른 접근 방식이 필요했습니다. 비록 약간의 리팩터링은 필요했지만, 팀원들은 새로운 추상화나 추가적인 함수를 만들어낼 필요가 없었습니다. 작업의 대부분은 언어의 문법 그대로를 사용함으로써 구현되었습니다. (syntatical in nature) 또한 그들은 몇개의 추상화 계층을 덧댐으로써 코드 베이스의 크기를 큰 폭으로 줄일 수 있었습니다.
KN 아까 ‘제 취향은 일단 프로젝트를 시작하고 빠르게 일들을 처리하는’거라고 하셨죠. 저도 그 말에 100% 동감합니다. 프로젝트를 이제 막 시작하는 시점에서는 무엇을 최적화해야 할 일이 생길 지를 알 수가 없기 때문에 ‘변화할 수 있는 가능성’을 최적화시키는게 좋단 것이 제 관점입니다.
그래서 저는 당신이 어떤 식으로 코드를 구조화시켰는지, 초기에 빠르게 작업을 진행하고 추후에 프로젝트의 제약사항이 점점 뚜렷해지는 와중에도 그 속도를 유지하기 위해 어떤 방법을 사용했는지가 궁금하네요.
KP 그 당시 우리 팀원의 대부분은 Ruby on Rails 개발자였기때문에, 우리는 Rails 세계에서 사용되는 개념(terminology)들과 디렉토리-트리 구조에 익숙했습니다. 우리는 그 개념들을 Node에도 그대로 적용했고, 덕분에 빠르게 시작할 수 있었죠. Node도 Rails 처럼 몇몇 기초적인 기능들을 충실하게 가지고 있었다는 점도 도움이 되었지요. 하지만 우리가 어떻게 구조를 잡아야 할지, 그리고 어떤 식으로 해야 할지에 대한 가이드가 없었기 때문에 조금 걱정되기도 했습니다.
두 번째로 도움이 된 것은, 우리가 모든 컨트롤러와 뷰를 클라이언트 측에 넘기고, 모든 모델들을 백엔드 쪽에 배치하기로 결정한 것이었습니다. 디렉토리 구조의 관점에서, 이것은 우리의 모델 구조나 뷰 디렉토리에 아무 파일도 가지고 있지 않다는 것을 의미합니다. 우리가 ‘컨트롤러’라는 표현을 쓰긴 했지만, 우리는 사실 어떤 입력을 받고, 몇 번의 요청을 날리고, 그것들을 포매팅해서 뱉어내는 포매터를 만들고 있는 것이나 다름없었습니다.
이 사실은 우리가 Rails의 구조를 가지고 있으면서도 대부분의 디렉토리가 비어 있다는 사실을 의미하기도 했습니다. 하지만, 한편으론 그건 좋은 일이었어요. 우리는 그 디렉토리를 그대로 내버려 두어서 사람들이 그 디렉토리에 뭔가를 만들게 하지 못하게 했습니다. 그건 마치 “이 디렉토리에 뭔가를 만들기 시작한다면 우린 뭔가 잘못하고 있는겁니다.”라고 말하는 코드 리뷰 도구를 가지고 있는 것과 비슷했습니다. 그리고 이것은 어떻게 노드를 사용할지에 대한 서버 디자인 패턴에서 나왔습니다.
우리가 초기에 했던 일 중에 또 한가지 도움이 되었던 것은 기본적인 테스팅 환경과 프레임웍을 세팅한 것이었습니다. Python의 Django 프레임워크처럼 Rails역시 TDD(Test-Driven Development)나, BDD(Behavior-Driven Developement)에 크게 의존하고 있어서 코드를 작성하기 전에 테스트와 결과들을 작성해야 합니다. 이것은 테스팅 프레임워크가 있을 때 정말 잘 작동하는 방식이죠. 우리는 이미 테스팅 프레임웍을 가지고 있었고 이것을 디렉토리의 구조의 최상위와 소통할수 있게 작성한 몇 개의 스크립트를 연동함으로써 디렉토리 구조에 적용시켰습니다. 우리는 처음에 Vow를 사용하여 시작했지만, 3달 후에는 결국 모든 테스트를 Mocha로 작성하게 되었습니다.
테스팅 환경과 프레임워크를 세팅하는 일이 또 하나의 코드 패턴에 불과하다고 생각할 수도 있지만, 아마도 다른 언어로 테스팅을 작성하기는 더 어려웠을 겁니다. 특히나 Node의 이벤트 기반 특성을 다룰때는 더더욱 말이죠. 결국 코드를 리팩터링해야 하긴 했지만, 새로운 추상화 계층이나 추가적인 함수들을 작성해야 하는 큰 일은 발생하지 않았습니다. 우리가 했던 일의 대부분은 언어의 신택스 레벨에서 지원되는 내용이었습니다. 그리고 거기에는 함수형 언어로서의 특징이, 아주 사소하지만 많이 작용했죠. 예를 들어, Node의 컨셉 중에는 ‘모든 콜백에서 첫 번째 인자는 에러여야 한다’ 같은 것이 있죠. 직관적으로 이해가 되지 않나요?
하지만 그 다음 두번째, 세번째, 네번째 인자는 무엇인지 알 수가 없죠. 아니면 인자가 딱 하나뿐일 수도 있고, 다섯개일 수도 있잖아요? 이런 문제들을 어떻게 해결할까요? 그리고 그 콜백이 처리된 다음은 무슨 일이 일어날까요? 이제 콜백 함수의 시그니쳐를 바꾸고 싶다고 생각해봅시다. 당신은 어떻게 그 함수를 호출하고 콜백을 기다리던 친구들에게 어떻게 그 사실을 알릴까요? 이게 Node만의 문제인지 아니면 모든 Javascript의 공통적인 문제인지는 알 수 없지만, 우린 이 방법을 찾아내는 데에 약간의 시간이 걸렸습니다.
KN 당신의 팀원들은 인터페이스 경계에 대해 어떻게 커뮤니케이션 했나요? 정적 타입을 사용하는 데에 익숙해진 사람들은 인터페이스를 포기하려고 하지 않더군요. 왜냐하면 인터페이스라는 것은 다른 팀 멤버에게 “이게 내 의도야. 나는 네가 이걸 이런식으로 호출해주기를 바라고 있어.” 라고 말하는 구체적인 문서의 형태를 제공하니까요. 더 중요한 것은 그 호출 방법이 존재하지 않는다면, 그건 사실 당신이 생각해보지 못한 유즈 케이스라는 의미일 것이고 작동하지 않을 텐데요.
KP 저는 두 가지의 인터페이스가 존재한다고 생각합니다. 하나는 코드 내부의 라이브러리 사이의 인터페이스이고, 두번째는 클라이언트와 서버 사이의 인터페이스입니다. 클라이언트와 서버 사이의 인터페이스의 경우, 저희는 REST (REpresentational State Transfer) 를 사용했고, Node 서버에 의해 반환되는 매우 잘 정의된 모델을 가지고 있었습니다. 저희 팀은 그걸 “뷰 기반 모델”이라고 불렀죠. 저희는 단순히 그것을 문서화했고, “이봐, 여기 REST 인터페이스과, 그걸 우리가 어떤 식으로 지원하는 지가 나와 있어.” 라고 이야기했죠. 그것들은 버전 관리되는 인터페이스 구조들 사이에 존재했습니다. 사실 이건 전통적인 REST죠.
코드 베이스 내부에서는, 저희는 모듈 시스템을 매우 많이 사용했습니다. 각각의 REST 엔드포인트는 그 엔드포인트에서의 모든 응답들과, 그 루트에 매핑된 모듈에 대한 퍼블릭 인터페이스를 나타내고 있는 파일 하나씩을 가지고 있습니다. 당신은 원하는 만큼 많은 수의 함수를 작성할 수 있지만, 작성하는 모든 함수는 모듈 밖으로 내보내질(export) 것입니다. 결국 당신은 내보내질 함수들의 목록을 작성해야 하게 되고, 그것을 우리는 인터페이스로 사용했습니다.
KN 또 하나 커뮤니케이션에서 중요하게 생각해야 할 점 중의 하나는, 그것이 팀원들로 하여금 오류를 낼 확률이 높게끔 코드를 작성하지 않는 습관을 들이게끔 돕는지의 여부라고 생각합니다.
KP 저희가 처음 이걸 시작했을 때, 저희 팀은 4명에 불과했기 때문에 팀원들이 체크인하는 모든 코드를 지켜볼 수 있었습니다. 제가 이상한 걸 볼때마다, 저는 그것에 대해 물어봤습니다. – 제가 그것이 틀렸다고 생각해서만은 아니고, 왜 우리가 이런 패턴을 사용해야만 하는지를 이해하고 싶었기 때문에요. 왜 코드들이 이런 식으로 작성되었는지, 그리고 다음엔 어떻게 되어야 하는지를 이해하는 것은 어렵지 않았습니다. 현재 팀은 훨씬 더 커졌고, 저희는 저희가 예전에 내렸던 기술적 결정의 의미에 대해 공유하고 있는데, 이것은 확실히 더 어렵습니다. 이제 저희는 새로운 사람이 팀에 들어올 때마다 3~5일간의 사전 교육을 거치고 있습니다. 이를 통해 우리는 “우리는 이런 식으로 이 일을 해결한다. 이게 약간 이상해 보일 수 있다는 것은 이해하지만, 이것이 우리가 이런 방식을 사용하는 이유이다.” 란 사실을 설명할 수 있는 기회를 얻습니다. 제 생각엔 이것이 코드 패턴을 설명하는 가장 좋은 방법인 것 같습니다.
TC 그 코드 패턴 중에 어떤 것이 가장 중요하다고 생각하십니까?
KP 저희는 흐름 제어 라이브러리로 Step을 사용하기로 결정했습니다. Step은 두 가지의 핵심 구조를 가지고 있는, Stem의 아주 간단한 버전입니다. 우리는 이 라이브러리에 약간을 추가해서 세 가지의 구조를 만들었습니다. 기본적으로 Step은 폭포수 콜백(waterfall callback)이라는 개념을 가지고 있는데, 당신이 Step으로 함수의 배열을 넘겨주면 Step은 각각의 함수를 순서대로 호출하여 첫번째 함수를 호출함으로써 얻어지는 값을 두번째 함수에 넘겨주고, 이와 같은 방식으로 반복합니다. Step은 함수가 비동기적으로 실행될 때도 – 이벤트 기반의 무언가를 실행할 때도 – 이 실행 순서를 보장하기 때문에, 함수가 콜백을 넘겨받으면 그 함수의 실행이 완료되고 나서 딱 한번만 그 함수를 호출하게 됩니다. 그 함수가 동기적이든 비동기적이든 상관없이, 폭포수 콜백은 순서에 맞추어 실행될 것입니다.
Step은 그룹 메소드(group method)와 병렬 메소드(parallel method) 역시 제공합니다. 저희는 그룹 메소드를 매우 많이 사용합니다. 이를 통해 함수들의 그룹을 넘겨주고, 함수들을 모두 병렬로 실행시킨 후에, 실행이 모두 끝나면 리턴하게 할 수 있죠.
하지만 이 중에 한 가지 문제가 있었습니다. 우리가 세 개의 함수로 되어있는 그룹을 가지고 있는데 그 중 하나의 함수에 문제가 있다면, Step은 나머지 두 개의 함수에 대해 반환값을 체크하지 않을 것입니다. 대신 콜백을 실행시켜서 “미안해요. 에러가 났네요” 라고 말합니다.
제가 여섯 개의 함수를 호출했는데 그 중에 두 개는 필수적이고 나머지는 부가적 (optional) 이라면 나머지들을 모두 일정한 타임아웃까지 기다린다 해도 별 문제가 되지 않을 것입니다. 하지만 부가적인 것들이 오류가 난다면 블록 전체가 에러난 것 같이 보이게 될 것입니다. 이건 우리가 바라던 바가 아니었습니다. 따라서 우리는 GroupKeep이라는 함수를 만들어서, 주어진 모든 함수들을 실행시키고 오류가 있다면 배열 안에 담아두도록 작성했습니다. 오류의 배열 상 위치를 보고, 이 오류가 꼭 필요한 항목에서 난 것인지 아니면 부가적인 항목에서 난 것인지를 정확히 알 수 있습니다. 이를 통해 우리가 필요할 때마다 프로세스가 계속되도록 코드를 작성하는 것이 가능해졌습니다.
가볍고 빠른 Node.js의 특성은 다른 무엇보다도 Prasad와 그의 팀에게 매력적이었습니다. 이를 통해 코드 크기 역시 매우 큰 폭으로 – 수천 라인에서 60,000 라인 정도 – 줄어든다는 것이 밝혀졌습니다.
또한 그 코드들은 프레임워크를 필요로 하지 않았기 때문에, 그에 따라 부가적인 코드 역시 줄어들었습니다. 무엇보다도, Node의 이벤트 기반 방식은 더 적은 리소스를 필요로 했고 더 많은 기능들을 클라이언트 쪽으로 이동시켰습니다. 최종적으로 이것은 추가적인 추상화 레이어를 함수 기반의 접근 방법을 통해 구현하도록 했습니다. 결과적으로, 이 모든 것들은 많은 수의 사용자들이 다양한 디바이스를 통해 실시간으로 서비스에 접근하는 것을 가능하게 했습니다.
TC 당신이 처음 얼마나 빠르게 Node 프로토타입을 만들고 테스트할 수 있었는지에 이야기하는 동안, 저는 그것이 실제 작성하는 코드의 양을 줄였을까 하는 궁금증이 생겼습니다.
KP 물론입니다. 저희의 Node 코드 베이스는 초기 버전에 비해 약간 커지기는 했지만, 아직 1,000 라인에서 2,000 라인의 코드로 구성되어 있습니다. 이에 대조적으로 저희가 예전에 사용했던 루비 코드 베이스는, 60,000 라인의 코드로 되어 있습니다. 이렇게 코드 크기가 줄어들 수 있었던 가장 큰 이유는 현재 저희의 코드 베이스가 프레임워크를 사용하지 않아서 필요한 것 이외의 자잘한 코드가 없기 때문입니다.
두 번째 이유는 저희가 현재 사용하고 있는 함수적인 접근 방법과 관계가 있습니다. 이것은 기존의 객체 지향과 대비되는 것으로서, 저희에게 중요한 변화였음이 확인되었습니다. Ruby에서는 모든 커뮤니케이션과 타입을 캡슐화하는 객체를 만드는 것이 자연스러운 방향입니다. 사실 Ruby는 함수형 언어임에도 불구하고, Javascript에 비해 훨씬 더 클래스와 객체를 강조하고 있습니다. 그래서 저희의 예전 코드 베이스에서 우리는 아주 많은 수의 추상화 계층을 가지고 있었고, 더 큰 컴포넌트의 개발과, 리팩터링과 재사용이 가능한 코드를 만들기위해서 수많은 객체들을 만들어야 했습니다. 하지만 돌이켜보면 그 중의 대부분은 우리가 정말 필요한 것은 아니었습니다.
코드 크기가 줄어든 주요한 요인 중의 하나는 MVC (Model-View-Controller) 모델에 숨어있던 관성(Momentum)이었습니다. 적어도 모바일 기반시스템과 웹 기반 시스템을 비교해보았을 때는요. 기존에 저희는 대부분 서버사이드 렌더링을 사용했습니다. 하지만 템플릿과 뷰를 클라이언트 사이드로 옮기자 (물론 렌더링도요) 많은 코드가 흔적도 없이 사라졌습니다. 그와 함께 모델들이 있는 백엔드는 검증(validation)과 더 복잡한(advanced) 작업들이 실행되는 곳이라는 믿음과 확신을 얻었습니다. 이것은 데이터들을 중복 체크할 필요가 없다는 것을 의미하고, 이로 인해 또 많은 코드들을 제거할 수 있게 되었습니다.
KN 당신이 아까 언급하기를 Node.js로 코드를 재작성하기를 결정하는데 도움이 된 것 중에 하나는, 사실은 당신이 다루고있는 객체들에 대해 깊게 이해할 필요가 없다는 사실을 깨달았다는 것이라고 말씀하셨죠. 이것은 당신이 그 객체들을 많이 변화시키지 않는다는 사실을 의미합니다. 기본적으로는 해시를 합치는 작업만을 하신다고요. Ruby 같은 언어도 해시맵 자료 구조를 기본적으로 가지는데, 이런 언어를 가지고서도 같은 결론에 도달하셨을 것이라고 생각하십니까?
KP 아마도 그렇겠지만, 아마 당신이 Ruby를 본다면 Rails에는 매우 많은 부가적인 요소들이 들어가 있다는 사실을 알게 될 겁니다. 반면 Node 바이너리에는 HTTP 서버/클라이언트만이 같이 들어가 있죠. 이는 HTTP Node 모듈과 HTTP 리스닝 모듈이 따로 필요하지 않다는 뜻입니다.
그러니까 제 대답은, 우리가 모든 객체 구조들을 제거하고 해시 자료구조만을 사용해야만 했다면, Ruby를 사용할 수도 있었을 겁니다. 하지만 당신은 또한 HTTP 리스닝을 하고, 그걸 컨트롤러에 넘기고, 결국 자잘한 계층들을 더해야 할 것입니다. 그런 계층들은 당신이 쓸 필요가 없는 코드를 제공해주기는 하지만, 동시에 모든 것들을 프레임워크와 잘 작동하도록 작성해야 하는 요구사항이 생기는 측면도 존재하지요.
TC 만약 비슷한 프로젝트를 막 시작하려고 하는 누군가와 이야기 한다면, 어떤 점들에 대해서 “이걸 주의하지 않으면 문제가 생기게 될꺼야” 라고 말해주고 싶나요?
KP 흐름 제어 (flow control) 과 예외 처리입니다. 이건 Node에 한정된 문제만은 아니지만, 전 이것에 대해 “최대한 가볍게, 최대한 얇게.” 라고 말해주고 싶네요. 제 생각에 사람들은 이런 경향이 있는 것 같습니다. “HTTP를 처리하는 뭔가가 필요하니, 그걸 해주는 모듈을 찾아야지.” 그러면 4,000 줄의 코드 덩어리가 뚝 하고 그들의 환경에 떨어지게 되죠. 그들이 필요한 것은 단지 HTTP 리퀘스트 하나 뿐인데도요. 결국 사람들은 필요한 것 이외에도, 그 밖의 쓸데없는 것들 한 뭉치를 같이 제공하는 짱짱 모듈을 사용하게 됩니다.
기본적으로 Node가 이토록 빠르고 좋은 이유는 가볍고 얇기 때문입니다. Node는 그 안에 거의 아무것도 가지고 있지 않아서, 작은 것 하나 하나를, 쓰고자 하는 Node 모듈을 하나씩 추가할 때마다, 그것은 비용이 되어 돌아옵니다.
KN 이미 Node로 프로젝트를 런칭한 회사들에게 그들의 생태계에 더한다면 더 강력해질만한 세 가지를 추천해준다면 어떤 것들이 될까요?
KP 첫 번째는 좋은 IDE입니다. IntelliJ IDEA는 매우 좋지만, 그걸 제외한다면 전 Node를 위한 좋은 IDE나 도구모음을 본 적이 없네요.
두 번째는 성능 분석과 모니터링을 발전시키는 것입니다. 보다 발전된 오퍼레이션 모니터링 툴도 좋지만, 당신이 모니터링 훅을 코드에 삽입하기 전까지는 블랙박스일 뿐입니다. 저는 Java VM이 제공하는 JMX 레이어에 있는 이런저런 것들을 찾아보는 것을 좋아해요. 당신도 거기서 몇몇 유용한 정보들을 얻을 수 있을 것입니다.
그리고 세 번째는 New Relic입니다. 당신의 Node 시스템이 무엇을 하고 있는지를 검사할 수 있고, 당신의 어플리케이션을 구체적으로 분해함으로써 어느 곳이 병목인지, 어떤 곳에서 성능 저하가 일어나는지 관찰할 수 있습니다. 이건 정말 끝내주죠.
로그인을 필요로 하는 웹사이트에서 로그인을 할 때 아이디 저장이라는 체크 박스를 보았을 것이다.
체크 박스에 체크를 하면 그다음 접속 시에 전에 입력한 아이디가 저장 되어 있는..
어떻게 이런일이 벌어질까..?
쿠키에 저장을 해놓고 다음 접속시 쿠키에 있는 값을 불러들여 화면에 표현해 주면 된다.
일단 순서는 아이디를 입력하고 체크 박스에 체크 후 로그인 버튼을 누르게 되면..
체크박스에 체크가 되어 있는지 되어 있지 않은지부터 확인을 하고..
체크가 되어 있다면 입력한 아이디를 쿠키에 저장 하기만 하면 된다.
저장 후 다시 불러 오는것은 화면이 불러와 지는 순간 쿠키에 아이디가 저장이 되어 있는지 되어 있지 않은지를
확인하여 화면에 표현해 주기만 하면 된다.
위의 기능들은 자바스크립트로 구현하였다.
소스코드는 아래와 같다.
// 쿠키에 id를 저장.
function setsave(name, value, expiredays) {
alert(“cookie Save!!”);
var today = new Date();
today.setDate(today.getDate() + expiredays);
document.cookie = name + “=” + escape(value) + “; path=/; expires=”
+ today.toGMTString() + “;”;
alert(“cookie Save Complete!!”);
}
// 버튼 클릭시 실행 function
function saveId(){
//if (document.getElementById(“idcheck”).checked) {
saveLogin(document.getElementById(“userId”).value);
//} else {
//saveLogin(“”);
//}
}
// id를 받아와 쿠키에 저장할지 쿠키에서 삭제할지 결정.
function saveLogin(id) {
if (id != “”) {
// userid 쿠키에 id 값을 7일간 저장
setsave(“userid”, id, 7);
} else {
// userid 쿠키 삭제
setsave(“userid”, id, -1);
}
}
// 화면 로드시 아이디
function getLogin() {
// userid 쿠키에서 id 값을 가져온다.
var cook = document.cookie + “;”;
var idx = cook.indexOf(“userid”, 0);
var val = “”;
if (idx != -1) {
cook = cook.substring(idx, cook.length);
begin = cook.indexOf(“=”, 0) + 1;
end = cook.indexOf(“;”, begin);
val = unescape(cook.substring(begin, end));
}
// 가져온 쿠키값이 있으면
if (val != “”) {
document.getElementById(“userId”).value = val;
document.getElementById(“idcheck”).checked = true;
}
}
<BODY onLoad=”getLogin()”>
<input type=”button” id=”changeColorButton” value=”Click~!” onClick=”saveId();”>
<input type=”text” name=”userId” id=”userId” />
<input type=”checkbox” name=”idcheck” id=”idcheck”/>
</BODY>
버튼 클릭시 saveId() function을 실행하여 체크박스가 체크 되어있는지 되어있지 않은지 부터 확인한다.
체크가 되어 있다면 saveLogin(id) function에 입력한 아이디 값을 파라미터로 넘겨준다.
입력한 아이디 값의 유무를 확인하여 쿠키에 저장을 할지를 결정..
쿠키에는 저장할때의 키값과 아이디값 그리고 쿠키에서 저정할 기간을 저장..
이러면 저장은 완료가 된다.
그다음 쿠키에서 아이디값을 불러오는 방법..
화면이 로드 될 때 getLogin() function을 실행하여 쿠키안에 아이디 저장할때 쓰였던 키값이 있는지 없는지를 체크하여
있다면 화면에 보여주면 된다. 덤으로 체크박스에 체크도 해줘야 한다.
워드프레스 버전을 거진 1년 만에 업데이트 완료 했네요 ^^;
귀차니즘으로.미루고 미루다가 결국 ..
자동업데이트 하다가 FPT 설정이 잘못되있어서 꽤 애먹었습니다 ㅠ_ㅠ
2014년에는 더욱더 블로깅을 열심히 해보자는 의미에서 ㅎ 업데이트 !
ㅎㅎ 화이팅
JSTL 반복문인 forEach 문에서 변수 2개이상 값을 반복하는 방법을 알아보겠습니다.
<c:forEach var=”vo” items=”${value}” begin=”0″ end=”${result_size }” varStatus=”status”>
${vo.dto}
</c:forEach>
다음과 같이 jstl 을 사용하여 반복 하는 쉬운 예입니다.
2개 이상 값을 반복 하고 싶다면..
<c:forEach var=”vo” items=”${value}” begin=”0″ end=”${result_size }” varStatus=”status”>
${vo.dto}
${add_value[status.index].add_dto }
</c:forEach>
위에 빨간 부분을 추가 해주시면 됩니다.
list 에 담긴 변수를 하나씩 꺼내 올수가 있습니다.
[status.index] 이 내용은 현재 반복 횟수를 나타내 줍니다.
그럼 우리가 자바 에서 쉽게 사용하는 value[] 배열 형태를 출력해 주신다고 생각하면 되겠습니다 .^^
이상 끝 !

